Download to read offline



![Natural?
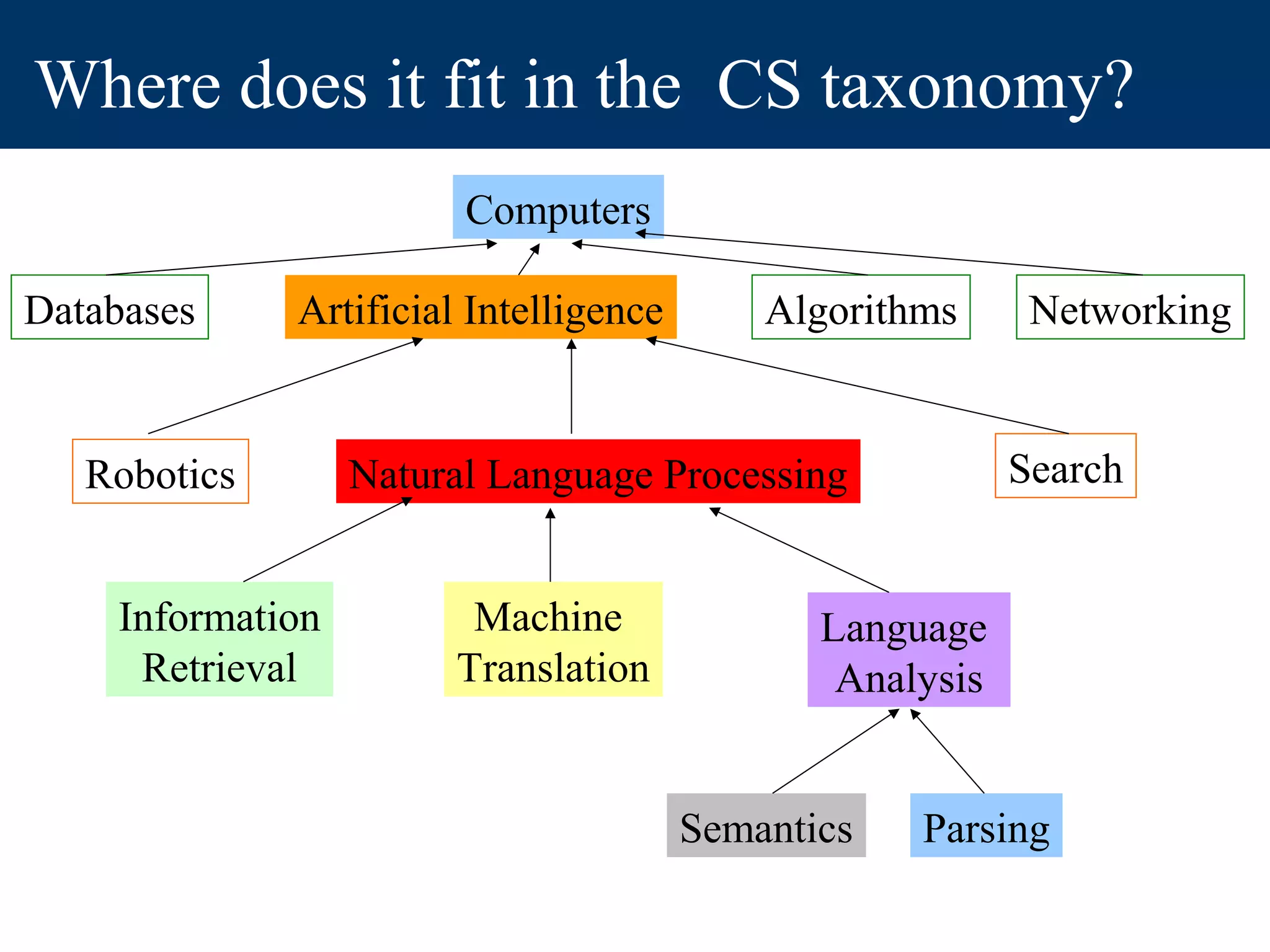
• Natural Language?
– Refers to the language spoken by people, e.g. English,
Japanese, Swahili, as opposed to artificial languages, like
C++, Java, etc.
• Natural Language Processing
– Applications that deal with natural language in a way or
another
• [Computational Linguistics
– Doing linguistics on computers
– More on the linguistic side than NLP, but closely related ]](https://image.slidesharecdn.com/intro-120910093829-phpapp01/75/Intro-4-2048.jpg)




![Issues in Syntax
• Shallow parsing:
“the dog chased the bear”
“the dog” “chased the bear”
subject - predicate
Identify basic structures
NP-[the dog] VP-[chased the bear]](https://image.slidesharecdn.com/intro-120910093829-phpapp01/75/Intro-10-2048.jpg)



![Why Semantics?
• The sea is at the home for billions factories and
animals
• The sea is home to million of plants and
animals
• English French [commercial MT system]
• Le mer est a la maison de billion des usines et
des animaux
• French English](https://image.slidesharecdn.com/intro-120910093829-phpapp01/75/Intro-14-2048.jpg)








![Even More
• Discourse
• Summarization
• Subjectivity and sentiment analysis
• Text generation, dialog [pass the Turing test
for some million dollars] – Loebner prize
• Knowledge acquisition [how to get that
common sense knowledge]
• Speech processing](https://image.slidesharecdn.com/intro-120910093829-phpapp01/75/Intro-23-2048.jpg)




This document provides an overview of natural language processing (NLP). It discusses how NLP is used by major tech companies for applications like information retrieval, extraction, and machine translation. It also outlines some of the core challenges in NLP, including understanding syntax, semantics, anaphora resolution, and information extraction. The document concludes by listing some of the key topics that will be covered over the course of the NLP class, such as part-of-speech tagging, parsing, IR, question answering, and text summarization.



































































